blog
updates and short essays. Archive
Out of Touch: Economic News and Institutional Distrust
Working Paper
Abstract
Why have Americans lose faith in mainstream accounts of the economy? I propose mismatch-signaling theory: mainstream news signals elite beliefs, while online commentary signals public beliefs, causing elites to appear ``out of touch’’ when news signals diverge from audiences’ understanding of reality. I document a sustained mismatch between positive economic news and both negative sentiment and user commentary during the 2021–2025 vibecession in the United States: by 2022, consumer sentiment is better predicted by the tone of user comments than mainstream news. An original survey experiment shows that positive economic news causes economically dissatisfied readers to trust experts and media less, while juxtaposing positive news with negative user commentary causes trust declines even for readers without economic grievances. The results suggest a structural mechanism for institutional trust decline while highlighting the role of online commentary and news’ second-order effects in shaping political attitudes.
Digital Rubbernecking: Ranking Social Media Feeds Using Consumption Signals
Working Paper
Abstract
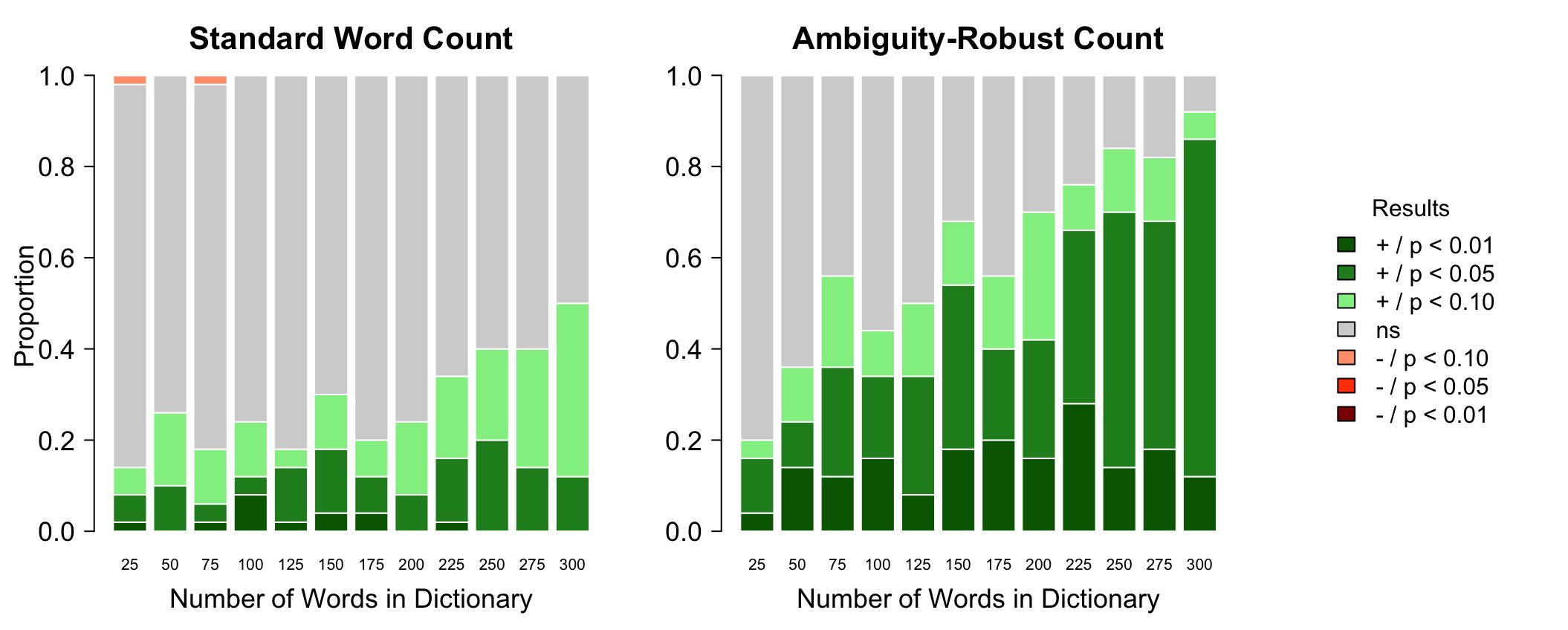
Social media platforms increasingly use consumption signals to rank content. Instead of relying on network based measures or predicted engagement (ie, likes or retweets), platforms simply optimize for whether users are likely to spend more time consuming content. We propose this leads to a phenomenon called digital rubbernecking, where content that is attention-grabbing because of toxicity or negativity is more likely to be surfaced in platforms that optimize for consumption. We test this using a simulated social media environment and custom-built ranking algorithms that either prioritize consumption or engagement signals.
Journalist Ideology and News Production: Evidence From Climate Coverage
Working Paper
Abstract
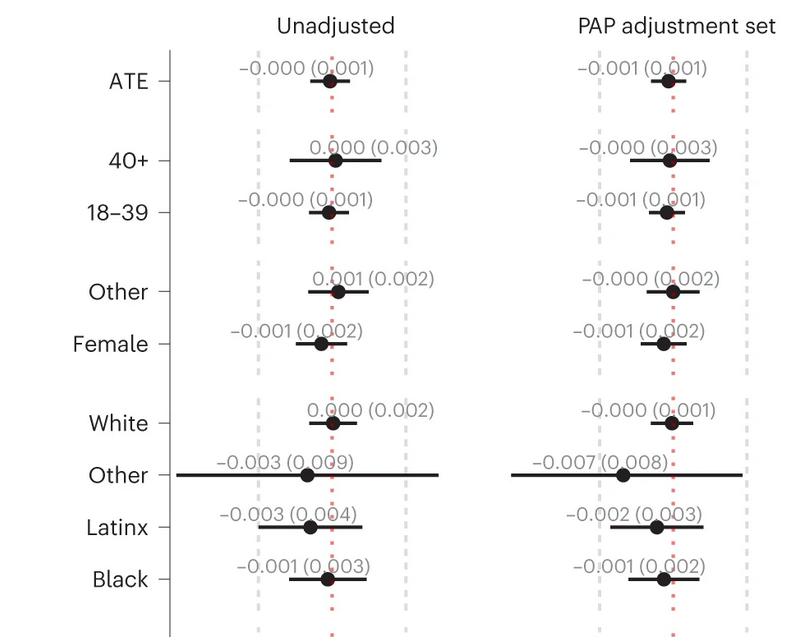
What role do journalists play in how political debates are portrayed in mainstream news coverage? We answer this question using data on climate change in Congressional floor speeches and in mainstream and partisan US newspapers from 2012-2022. We find that Republican lawmakers primarily discuss the costs of climate regulation while Democrat lawmakers primarily discuss the urgency of climate action. However, the climate debate in mainstream newspapers is predominantly focused on urgency. We propose a theory of journalist selection, arguing that this effect is driven by journalists increasingly self sorting into newsrooms based on their perceived ideological position. We find that journalists who join mainstream newspapers later are more likely to focus on urgency and less likely to focus on economic costs in their articles compared to older journalists in the same year, newsroom, and section. However, the opposite pattern holds for journalists who join far right partisan newspapers.
More














Sign up for the mailing list